Since you may wish to have access to your data after spinning down your cluster, Cortex's bucket, log groups, and Prometheus volume are not automatically deleted when running cortex cluster down.
To delete them:
# identify the name of your cortex S3 bucketawss3ls# delete the S3 bucketawss3rb--forces3://<bucket># delete the log group (replace <cluster_name> with the name of your cluster, default: cortex)awslogsdescribe-log-groups--log-group-name-prefix=<cluster_name>--querylogGroups[*].[logGroupName]--outputtext|xargs-I{}awslogsdelete-log-group--log-group-name{}
Delete Certificates
If you've configured a custom domain for your APIs, you can remove the SSL Certificate and Hosted Zone for the domain by following these instructions.
Keep Cortex Volumes
The volumes used by Cortex's Prometheus and Grafana instances are deleted by default on a cluster down operation. If you want to keep the metrics and dashboards volumes for any reason, you can pass the --keep-volumes flag to the cortex cluster down command.
Troubleshooting
On rare occasions, cortex cluster down may not be able to spin down your Cortex cluster. When this happens, follow these steps:
If you've manually created any AWS networking resources that are pointed to the cluster or its VPC (e.g. API Gateway VPC links, custom domains, etc), delete them from the AWS console.
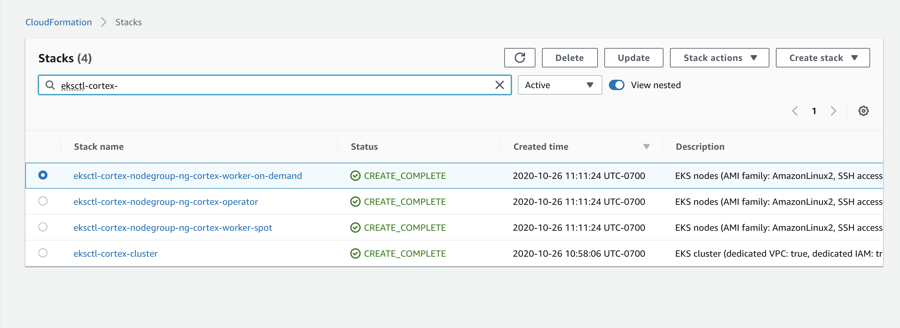
Replace "" and "" in the following URL, and open it in your browser: https://console.aws.amazon.com/cloudformation/home?region=<region>#/stacks?filteringText=eksctl-<cluster_name>-
For each CloudFormation stack which contains the word "nodegroup", select the stack and click "Delete".
Select the final stack (the one that ends in "-cluster") and click "Delete".
If deleting the stack fails, navigate to the EC2 dashboard in the AWS console, delete the load balancers that are associated with the cluster, and try again (you can determine which load balancers are associated with the cluster by setting the correct region in the console and checking the cortex.dev/cluster-name tag on all load balancers). If the problem still persists, delete any other AWS resources that are blocking the stack deletion and try again.
In rare cases, you may need to delete other AWS resources associated with your Cortex cluster. For each the following resources, go to the appropriate AWS Dashboard (in the region that your cluster was in), and confirm that there are no resources left behind by the cluster: CloudWatch Dashboard, SQS Queues, S3 Bucket, and CloudWatch LogGroups (the Cortex bucket and log groups are not deleted by cluster down in order to preserve your data).